About the Dataset
PIMA Indians Diabetes Dataset
Overview
The PIMA Indians Diabetes Dataset originates from the National Institute of Diabetes and Digestive and Kidney Diseases. It was collected to diagnostically predict whether a patient has diabetes based on certain medical measurements. All patients in the dataset are females of Pima Indian heritage, at least 21 years of age.
The dataset contains 768 records with
8 input features and a binary target variable
(Outcome): 0 indicates non-diabetic, 1 indicates diabetic.
It is widely used as a benchmark for classification algorithms in healthcare ML research.
| # | Feature Name | Data Type | Range | Description |
|---|---|---|---|---|
| 1 | Pregnancies |
Integer | 0 – 17 | Number of times pregnant |
| 2 | Glucose |
Integer | 0 – 199 | Plasma glucose concentration (2-hour oral glucose tolerance test, mg/dL) |
| 3 | BloodPressure |
Integer | 0 – 122 | Diastolic blood pressure (mm Hg) |
| 4 | SkinThickness |
Integer | 0 – 99 | Triceps skin fold thickness (mm) |
| 5 | Insulin |
Integer | 0 – 846 | 2-Hour serum insulin (mu U/ml) |
| 6 | BMI |
Float | 0 – 67.1 | Body mass index (weight in kg / height in m^2) |
| 7 | DiabetesPedigreeFunction |
Float | 0.078 – 2.42 | Diabetes pedigree function (genetic score) |
| 8 | Age |
Integer | 21 – 81 | Age in years |
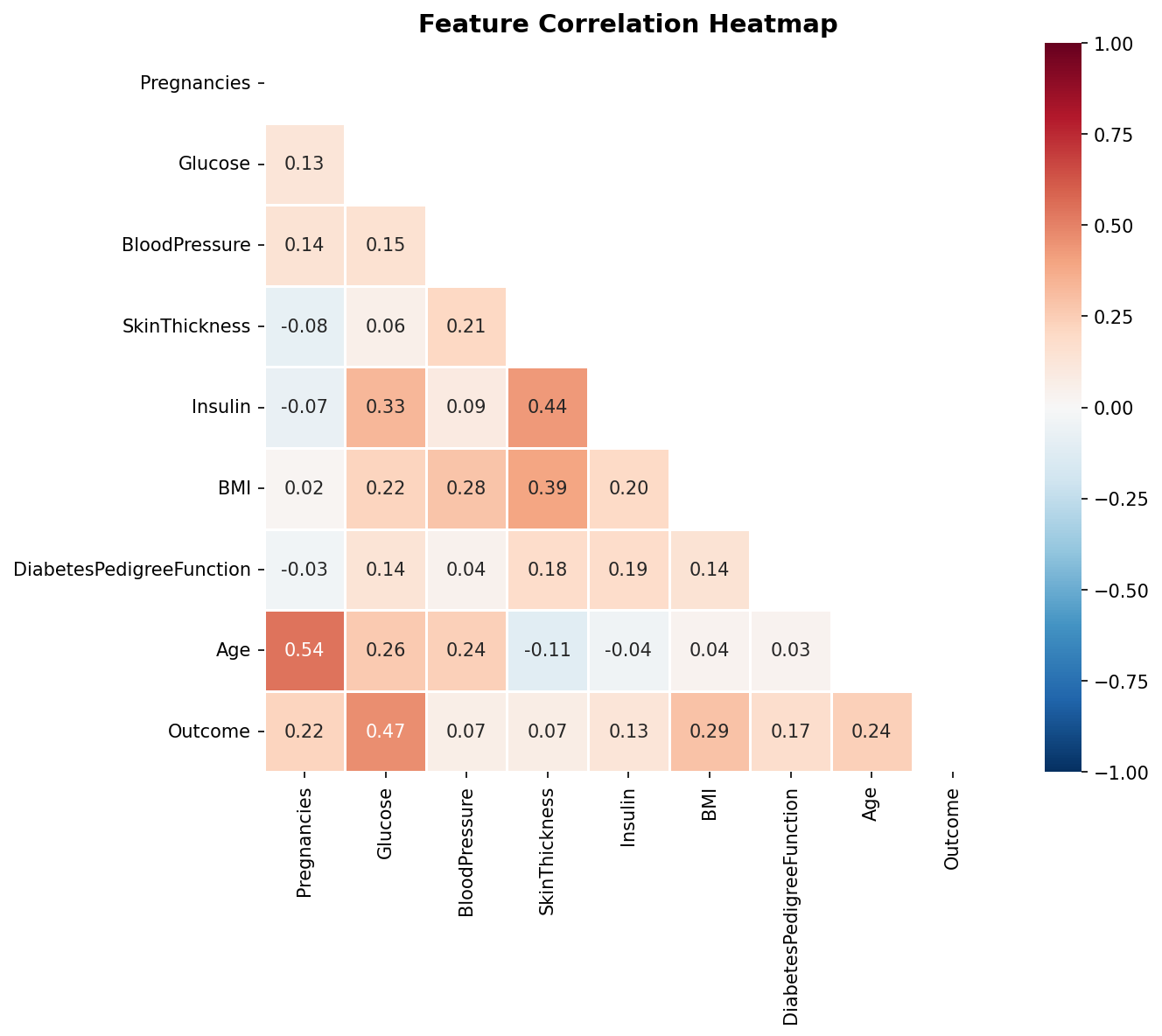
Data Source
National Institute of Diabetes and Digestive and Kidney Diseases
Originally published in: Smith, J.W., Everhart, J.E., Dickson, W.C., Knowler, W.C., &
Johannes, R.S. (1988). "Using the ADAP learning algorithm to forecast the onset of
diabetes mellitus." Proceedings of the Symposium on Computer Applications and
Medical Care, pp. 261–265.